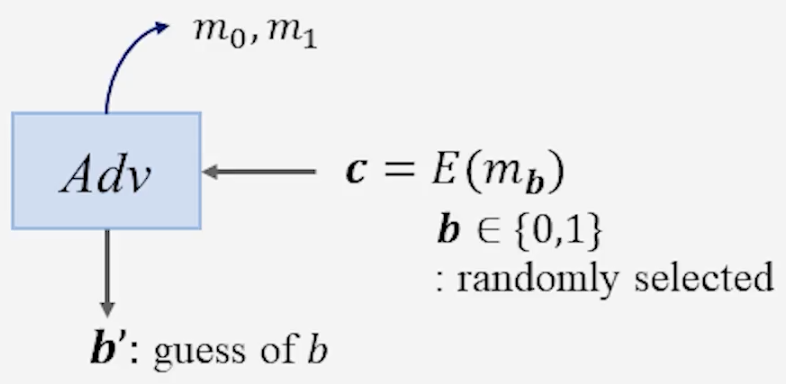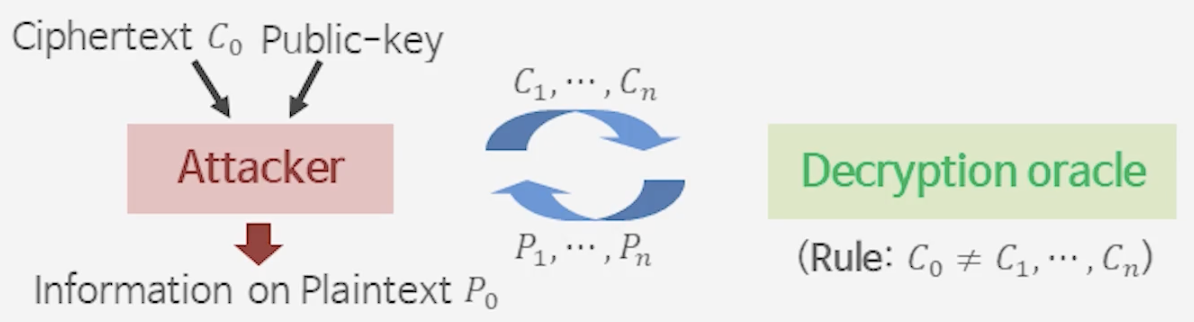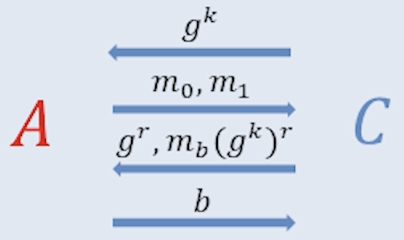OMSCS alumnus @ Georgia Tech. Focused on privacy-preserving machine learning and cryptography, developing methods for secure learning and unlearning systems to build AI that is both trustworthy and usable.
Here I keep structured notes on my explorations, shaped both by professional and personal experiences.
Primary Interest: Privacy-Preserving Machine Learning, Cryptography and Data Privacy
I am interested in developing secure and practical methods that protect sensitive data in machine learning and unlearning systems. My motivation comes from working with real-world data where privacy and usability often collide—whether in healthcare or finance. These experiences led me to focus on privacy-preserving machine learning (PPML) and cryptography as fundamental tools for building trustworthy AI systems.
Broader Interests: Animal and Human Communication
Beyond my core research, I am fascinated by how AI can help us better understand communication across species. After raising dogs for many years, I became curious about animal communication, service dogs, and broader human–animal interaction. This curiosity now extends to AI for animals, human activity recognition (HAR) and multimodal learning, where language, vision, and behavior intersect. I am currently exploring these interests through seminars and research activities such as DS@GT’s preparation for LifeCLEF 2026.
해당 포스트는 Ronny Ko의 저서 The Beginner’s Textbook for Fully Homomorphic Encryption을 기반으로 작성하였다. 이번 포스트에서는 ‘I. Basic Math: A-1. Modulo Arithmetic’ 파트를 요약•정리하고자 한다.
모듈러 (modulo, mod) 란, 한 수를 다른 수로 나눌 때 나머지를 계산하는 연산을 의미한다.
수식으로 표현하면 다음과 같다: \(A = BQ + R\)
$A$: 피제수 (dividend), $B$: 제수 (divisor)
$Q$: 몫 (quotient), $R$: 나머지 (remainder)
→ 따라서, “$A \bmod B = R$” 혹은 “$A$ modulo $B = R$” 로 표현할 수 있다.
$a \bmod q$ ( i.e., $a$ modulo $q$ ): $a$를 $q$로 나눈 나머지를 의미한다. 이때 나머지는 항상 $({0, 1, 2, 3, …, q-1})$ 사이의 값이다.
예: $7 \bmod 5 = 2$
모듈러스 (modulus): $a \bmod q$가 주어졌을 때, divisor q를 모듈러스라 부른다. 반면, 모듈러 (modulo)는 연산(operation) 자체를 의미한다.
모듈러 합동식 (Modulo Congruence): 두 정수 $a, b$가 $q$로 나눴을 때 같은 나머지를 가지면, $a$는 $b$와 모듈러스 $q$에 대해 합동이다. \(a \equiv b \bmod q ⟺ a = b \pmod q\)
예) $5 \equiv 12 \bmod 7$
$5 \bmod 7 = 12 \bmod 7 = 5$
주의: $b$를 $q$로 나누었을 때 나머지 $a$를 뜻하는 $a = b \bmod q$ 식과는 다르다.
합동식 vs 동치 (Congruence vs Equality): 임의의 정수 $k$에 대해서, \(a \equiv b \bmod q ⟺ a = b + k \cdot q\) → 즉, $a$와 $b$는 $q$의 정수배만큼 차이가 있을 때, 모듈러스 $q$에 대해 서로 합동이다.
예) $5 \equiv 12 \bmod 7 ⟺ 5 = 12 + (-1) \cdot 7$
2) 모듈러 산술 (Modulo Arithmetic)
📘 [Theorem A-1.2.1] Properties of Modulo Operations (모듈러 연산 성질)
모든 정수 $x$에 대해서, 다음이 성립한다:
Addition (덧셈): $a \equiv b \bmod q ⟺ a + x \equiv b + x \bmod q$
Subtraction (뺄셈): $a \equiv b \bmod q ⟺ a - x \equiv b - x \bmod q$
Multiplication (곱셈): $a \equiv b \bmod q ⟺ a \cdot x \equiv b \cdot x \bmod q$
📘 Proof (증명)
모든 정수 $x$에 대하여 다음이 성립한다:
Addition (덧셈): $a \equiv b \bmod q$ ⟺ $a = b+kq$ (임의의 $k$에 대해) # 이때 $a, b$는 $q$의 배수 차이를 가짐 ⟺ $a + x = b+k \cdot q + x$ ⟺ $a + x = b+x + k \cdot q$ # $a + x, b + x$는 $q$의 배수 차이를 가짐 ⟺ $a + x \equiv b + x \bmod q$
Subtraction (뺄셈): $a \equiv b \bmod q$ ⟺ $a = b+kq$ (임의의 $k$에 대해) ⟺ $a - x = b+k \cdot q - x$ ⟺ $a - x = b-x + k \cdot q$ # $a - x, b - x$는 $q$의 배수 차이를 가짐 ⟺ $a - x \equiv b - x \bmod q$
Multiplication (곱셈): $a \equiv b \bmod q$ ⟺ $a = b+kq$ (임의의 $k$에 대해) ⟺ $a \cdot x = b+k \cdot q \cdot x$ ⟺ $a \cdot x = b \cdot x + k_{x} \cdot q$ ($k_{x}=k \cdot x$ 일 때)# $a \cdot x, b \cdot x$는 $q$의 배수 차이를 가짐 ⟺ $a \cdot x \equiv b \cdot x \pmod q$
📘 [Theorem A-1.2.2] Properties of Modulo Arithmetic (모듈러 산술 성질)
Associative (결합법칙): $(a \cdot b) \cdot c \equiv a \cdot (b \cdot c) \bmod q$
Commutative (교환법칙): $(a \cdot b) \equiv (b \cdot a) \bmod q$
Distributive (분배법칙): $(a \cdot (b+c)) \equiv ((a \cdot b) + (a \cdot c)) \bmod q$
Interchangeable (치환 가능성): 모듈러 산술에서는 합동 관계에 있는 값 (congruent values) 은 연산에서 서로 자유롭게 치환 가능하다. - $(a \equiv b \bmod q)$와 $(c \equiv d \bmod q)$일 경우, 다음이 모두 성립한다:
$(a \cdot c) \equiv (b \cdot d) \equiv (a \cdot d) \equiv (b \cdot c) \bmod q$
📘 [Definition A-1.2.1] Inverse in Modulo Arithmetic (모듈러 산술에서의 역원)
모듈러 $q$ (즉, 모든 수를 $q$로 나눈 나머지의 세계)에서, 각 $a in {0, 1, 2, …, q-1}$에 대해 다음과 같이 정의된다.
Additive Inverse (덧셈 역원): $a_{+}^{-1}$은 다음을 만족하는 수이다. \(a + a_{+}^{-1} \equiv 0 \bmod q\) - 예. 모듈러 $11$에서 $3_{+}^{-1}=8$ → 왜냐하면 $3 + 8 \equiv 0 \bmod 11$이기 때문이다.
Multiplicative Inverse (곱셈 역원): $a_{*}^{-1}$은 다음을 만족하는 수이다. \(a \cdot a_{\*}^{-1} \equiv 1 \bmod q\) - 예. 모듈러 $11$에서 $3_{*}^{-1}=4$ → 왜냐하면 $3 \cdot 4 \equiv 1 \bmod 11$이기 때문이다.
Modulo Division (모듈러 나눗셈)
모듈러 산술에서의 나눗셈은 일반적인 수학적 나눗셈과는 다르다. (엄밀히 말하면, 모듈러 나눗셈은 존재하지 않는다.) 왜냐하면 모듈러 연산 자체가 이미 나머지를 구하는 일종의 나눗셈이기 때문이다.
하지만 어떤 수 $b$를 $a$로 “모듈러 나누기” 하고자 한다면, 이는 곧 $a$의 모듈러 역원 (modular inverse)을 이용한 곱셈으로 표현할 수 있다. \(b \div a \bmod q \; \equiv \; b \cdot a_{*}^{-1} \bmod q\) 즉, 모듈러 나눗셈(modulo division)은 모듈러 곱셈 (modulo multiplication)으로 정의된다.
📍 중요한 차이점:
일반적인 나눗셈은 실수(real number)를 결과로 내지만, 모듈러 나눗셈은 항상 정수(integer)를 결과로 낸다. (이는 $b$와 $a_{*}^{-1}$ 모두 정수이기 때문)
마지막으로, 정수 $a$의 모듈러 역원은 확장 유클리드 알고리즘 (Extended Euclidean Algorithm)을 이용해 계산할 수 있다.
중심 잔여 표현 (Centered Residue Representation)
Canonical은 0부터 시작하는 잔여계, Centered는 0을 기준으로 대칭인 잔여계다
지금까지 잔여(나머지, Residue)를 양의 정수(positive integer)라고 가정했다.
모듈러 $q$에서 가능한 나머지 집합은 다음과 같다. \({0, 1, 2, \dots q-1}\)
→ 이 표현 방식을 표준 잔여계(canonical residue system) 또는 비부호형 잔여 표현 (unsigned residue representation) 이라고 부른다.
🔸 하지만 또 다른 표현 방식도 존재한다. 바로 부호형 잔여계 (signed or centered residue system) 로, 잔여들이 0을 중심으로 대칭되게 분포한다. \({-\frac{q}{2}, -frac{q}{2}+1, \dots, 0, \dots, frac{q}{2}-2, \frac{q}{2}-1}\)
→ 비부호형 잔여계나 부호형 잔여계 모두 잔여의 개수는 동일하게 $q$개이다. 차이는 단지 잔여 범위의 기준점(upper/lower bound)에 있다.
💡 모듈러 연산의 역할 모듈러 연산은 주어진 값을 위 두 시스템 중 하나의 잔여 범위로 변환한다.
값이 상한보다 크면 → 모듈러스 $q$를 빼준다
값이 하한보다 작으면 → 모듈러스 $q$를 더해준다
→ 따라서 두 시스템의 차이는 단지 잔여의 “표현 방식”일 뿐, 모두 동일한 모듈러 집합 $\mathbb{Z}_q$를 나타낸다.
\[\mathbb{Z}_q = \{0, 1, 2, \dots, q - 1\}\]
Canonical과 Centered 잔여계는 모든 연산 성질이 동일하게 유지된다.
표준 잔여계(canonical system)와 중심 잔여계(centered system)는 덧셈 $\cdot$ 뺄셈 $\cdot$ 곱셈 $\cdot$ 나눗셈의 모든 모듈러 성질은 동일하게 성립한다.
\[(a \pm b) \bmod q, \quad (a \times b) \bmod q, \quad (a \div b) \bmod q\]
→ 이들이 어떤 잔여계에서 계산되든 결과의 동치 관계는 변하지 않는다.
💡 이유: 두 시스템 모두 같은 모듈러스 $q$를 사용하기 때문에, 어떤 두 동치 잔여(congruent residues)라도 서로 $kq$의 차이를 가진다. 즉, \(a \equiv b \pmod q \quad \Rightarrow \quad a - b = kq \quad (k \in \mathbb{Z})\)
→ 따라서 canonical 표현이든 centered 표현이든, 각 연산의 결과는 항상 같은 동치류(congruence class)에 속하게 된다.
Canonical과 Centered 잔여계의 연산 성질 중 역원도 동일하게 유지된다.
모듈러 $q$에서 $a$의 역원은 다음을 만족한다.
\[a \cdot a^{-1} \equiv 1 \pmod q\]
🔹 부호형(signed) 잔여 표현을 사용하는 이유는 특정 상황에서 모듈러 연산을 생략할 수 있을 정도로 계산을 단순화할 수 있기 때문이다.
#### 🧩 예제 1. Canonical (Unsigned) Representation 표준 잔여계에서는 \((a + b) \bmod q\) 의 형태를 가정하자. 만약 어떤 애플리케이션에서 항상 $0 \le a + b \le q - 1$ 이라는 조건이 보장된다면,
\[(a + b) \bmod q = a + b\]
따라서 모듈러 연산을 생략할 수 있다. (즉, 값이 잔여 범위 $[0, q-1]$를 벗어나지 않기 때문)
#### 🧩 예제 2. Centered (Signed) Representation 이번에는 중심 잔여계에서 \((a - b) \bmod q\) 를 생각하자. 만약 $a - b$가 항상 $[-\frac{q}{2}, \frac{q}{2} - 1]$ 범위 안에 있다면,
\[(a - b) \bmod q = a - b\]
이때도 모듈러 연산을 생략할 수 있다.
#### ⚠️ 주의: Canonical 표현에서의 뺄셈 만약 위와 같은 $(a - b) \bmod q$ 연산을 canonical 표현으로 계산한다면, $a - b$가 음수일 경우 그 값은 하한(0)보다 작아진다. 이 경우 모듈러스 $q$를 하나 이상 더해주는(modulo reduction) 보정이 필요하다.
예를 들어, \(a = 3, \quad b = 7, \quad q = 11\) 이면 \((a - b) \bmod 11 = (3 - 7) \bmod 11 = (-4) \bmod 11 = 7\)
✅ 정리:
canonical 표현: 음수가 되면 반드시 모듈러 보정 필요
centered 표현: ±범위 안이면 모듈러 보정 없이 연산 가능
즉, 부호형(centered) 잔여 표현은 덧셈보다 뺄셈 연산에서 더 직관적이며 효율적이다.
§D-5.8 절에서는 centered residue representation의 유리한 성질을 활용하여 FastBConvEx 연산(Fast Balanced Convolution Extension) 을 설계한다.
이 알고리즘에서는 다음과 같은 관계가 성립한다.
\[(\mu + u) \bmod b^{\alpha}\]
일반적으로는 모듈러 연산이 필요하지만, 이때 $\mu + u$가 항상 centered residue 범위 내에 존재함이 보장된다.
\[-\frac{b^{\alpha}}{2} \leq \mu + u < \frac{b^{\alpha}}{2}\]
따라서, \((\mu + u) \bmod b^{\alpha} = \mu + u\)
즉, 모듈러 연산을 생략하고 단순 덧셈으로 표현할 수 있다. 이는 연산을 간소화하고 계산 효율을 높이는 핵심 아이디어이다.
💡 핵심 포인트:
centered residue 표현을 사용하면, 값이 잔여 범위를 벗어나지 않는 한 모듈러 처리가 불필요하다.
이 특성은 고속 암호 연산(예: FastBConvEx) 설계 시 불필요한 나머지 계산을 제거하여 성능을 최적화하는 데 사용된다.
해당 포스트는 서울대학교 천정희 교수님의 암호론 강의를 기반으로 작성하였다. 이번 포스트에서는 ‘동형암호의 개요’에 대한 내용을 요약•정리하고자 한다.
동형암호의 개요
1) 동형암호란?
📘 4세대 암호
암호화된 상태에서 계산이 가능한 암호로, 키를 갖고 있지 않아도 계산이 가능하다. → 키를 보호하는 암호로, 키가 덜 사용된다는 측면에서 키의 안전성이 높은 암호이다.
미래 컴퓨팅 환경: 완벽한 하인!
우리가 하려는 일의 비밀을 알지 못한 채, 빠르고 정확하게 대신 수행하는 컴퓨터
📘 사례 모음집
사례 1: 개인 클라우드 - 데이터를 맡기되, 비밀은 지키기 (대칭키 동형암호)
스토리지 클라우드: Dropbox, Google email/calendar, NAS
사용자는 데이터를 암호화하여 저장하지만, 클라우드는 복호화 키를 모름 → 그래도 사용자는 평문처럼 검색하거나 접근 가능함
단순한 대칭키 암호는 서버가 데이터를 전혀 활용할 수 없지만, 대칭키 동형암호를 사용하면 암호문 상태에서도 검색·분석이 가능 → 예: 스팸 필터링, 파일 이름 검색 등
계산 클라우드: DNA 계산, 헬스케어, 개인성향분석을 통한 추천
개인의 민감한 데이터를 암호화한 채 클라우드에 맡겨 계산 가능
복호화 키는 오직 데이터 소유자가 보유 → 이러한 형태의 계산을 대칭키 동형암호라고 함
사례 2: 다수 사용자 통계분석 - 데이터를 공유하되, 통제는 유지하기
개인정보기반 마케팅 (구글, 페이스북, 네이버 등)
사용자의 데이터가 허용된 범위 내에서만 활용되도록 제한 가능 → 예: 내가 ‘광고에 사용’ 옵션을 허용한 경우에만 마케팅 분석 수행
동형암호를 통해 ‘데이터는 사용하되, 직접 보지는 못하게’ 할 수 있음*
정부 데이터베이스: 교육, 의료, 납세
기관 간 민감 데이터 교류시, 동형암호 기반 연산으로 프라이버시 보장 가능
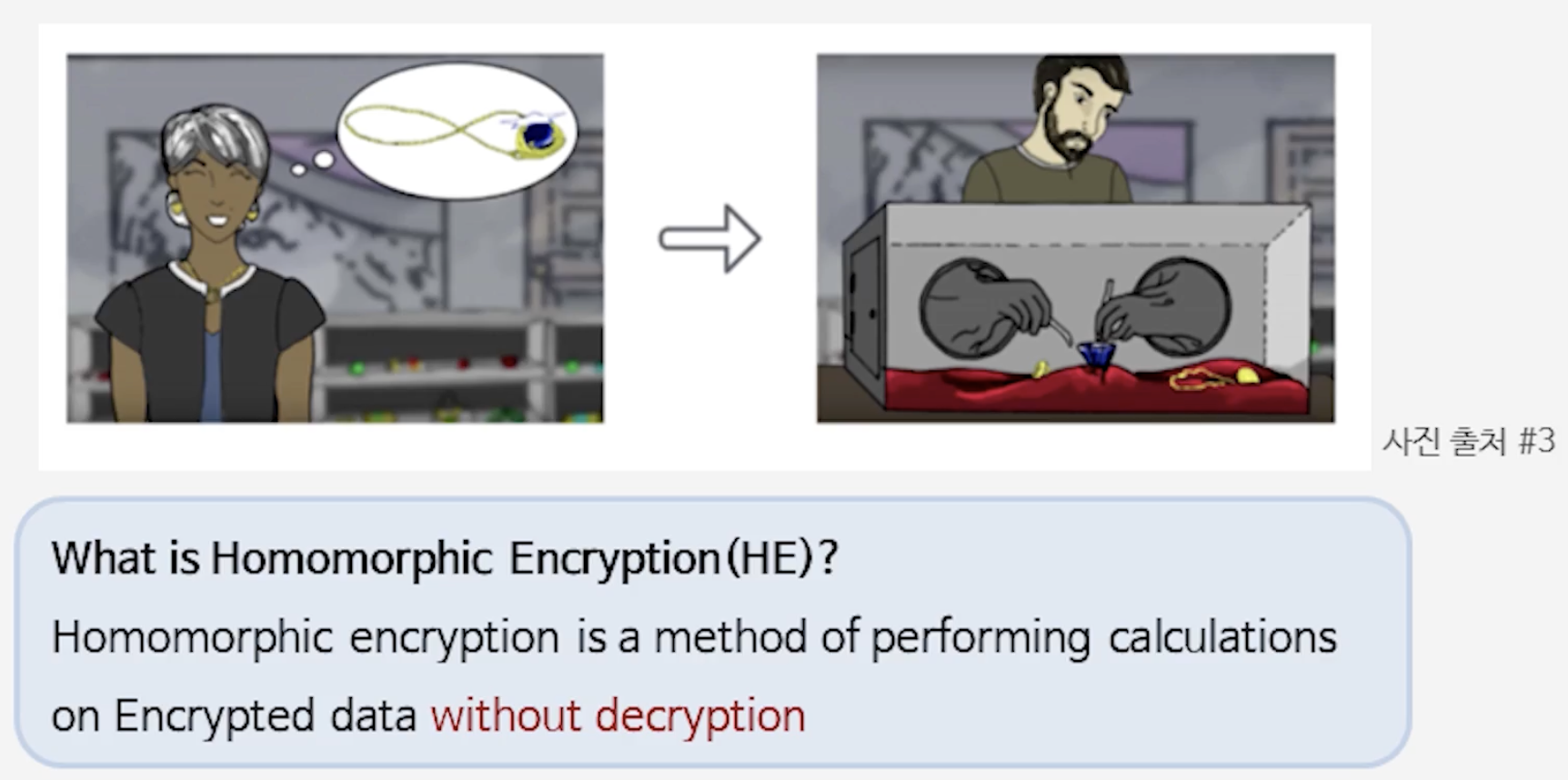
동형암호 (Homomorphic Encryption, HE)
복호화 없이도 연산이 가능한 암호화 기술, 즉 데이터를 보지 않고도 계산할 수 있는 암호
📘 참고. 영지식 증명 (Zero-Knowledge Proof, ZKP)
2017년, 영지식 (Zero-Knowledge) SNARG 계산 증명 기술 등장
연산 결과를 직접 공개하지 않고도 “올바르게 계산되었음”을 증명할 수 있음
즉, 비밀은 보호하면서도 신뢰를 확보하는 기술 → 대표 활용: 블록체인 개인정보 보호, 신원 인증, 거래 검증
📘 동형암호의 작동 원리
예를 들어, 우리가 1 + 2라는 단순한 계산을 하고 싶다고 하자. 하지만 계산의 내용을 클라우드에 노출하고 싶지 않다. 이때 우리는 각 값을 암호화하여 클라우드에 보낸다. 예를 들어, 1은 33, 2는 54로 암호화된다.
클라우드는 복호화 키를 전혀 알지 못한 채 단순히 암호문끼리의 덧셈(33 + 54)을 수행한다. 계산 결과로 얻은 87은 여전히 암호화된 상태이며, 우리는 이 값을 받아서 복호화하면 최종적으로 3을 얻는다.
이처럼 동형암호는 단순한 산술 연산뿐만 아니라 영상 처리나 머신러닝 모델 추론과 같은 복잡한 계산에도 확장될 수 있다. 예를 들어, 클라우드에게 두 장의 이미지를 암호화된 상태로 보내 “이 두 이미지가 같은지 비교해 달라”고 요청할 수 있다. 클라우드는 이미지 내용을 직접 보지 않고도 연산을 수행해 결과값만을 사용자에게 반환할 수 있다.
[그림] 동형암호의 핵심 원리: 암호문 위에서의 연산
📘 동형암호의 직관적 설명
간단한 비유로 설명하면, 전통적인 암호는 열쇠가 있어야만 여는 금고와 같습니다. 키가 없으면 그 안에 무엇이 있는지 전혀 알 수 없고, 아무런 조작도 할 수 없습니다.
반면 동형암호는 “말랑말랑한 금고”와 비슷합니다. 금고 안의 내용(평문)은 외부에서 보이지 않지만, 외부에서 손(연산)을 넣어 내부의 값을 가공할 수 있습니다. 즉, 클라우드(연산자)는 복호화 키를 알지 못한 채도 암호문 위에서 덧셈·곱셈 같은 연산을 수행할 수 있고, 최종 결과는 여전히 암호화된 상태로 반환됩니다. 사용자는 그 결과를 복호화해 실제 정답을 얻습니다.
예시: 의료 데이터의 경우, 환자의 원본 기록은 열리지 않은 상태로 보관됩니다. 연구자는 이 암호화된 데이터를 클라우드에 맡겨 통계분석이나 모델 추론을 수행하게 하고, 클라우드는 내용을 보지 못한 채 계산만 수행합니다. 계산 결과(예: 위험 지표)는 암호화된 상태로 돌아오고, 복호화 권한이 있는 사람만이 필요한 정보(예: 특정 진단의 유무 또는 요약된 수치)만 확인합니다.
핵심은 "비밀은 지키면서도 필요한 계산은 수행할 수 있다"는 점입니다. 이 성질 덕분에 동형암호는 개인정보·의료·금융 데이터의 안전한 외부 계산(클라우드 기반 분석, 암호화된 ML 추론 등)에 유용합니다.
[그림] 동형암호의 핵심 아이디어: 보지 않고 계산하기
동형암호의 장·단점
장점: 튜링완전성 (Turing-Complete)
암호화된 상태에서 AND, OR, NOT 연산이 모두 가능하다. 즉, 컴퓨터가 수행할 수 있는 모든 연산 (검색·통계처리·머신러닝)을 암호화된 데이터 위에서 수행할 수 있다. → 따라서 데이터 유출 위험을 원천 차단할 수 있다.
단점
암호문 크기 확장: 평문 대비 약 $10$ ~ $100K$배 (대칭키 방식은 약 $0.1$ ~ $1K$ 배 수준)
암·복호화 속도 저하: AES ≈ $1 us$, RSA ≈ $1 ms$, HE ≈ 수십 $ms$
암호문 연산 속도 저하: 특히 곱셈 연산은 평문 계산 대비 수백 배 이상 느림
응용별 성능 편차: 연산의 종류 (덧셈·곱셈·비교)에 따라 속도 차이가 크며, 효율을 높이기 위해 개별 최적화 알고리즘 및 구현 기술이 필요함 📘 예시 (복잡도 관점의 단순 모델)
- 128-bit 보안을 만족하기 위해 키 크기를 50배 늘린다고 가정하면, 계산량은 일반적으로 O(n^2) 복잡도를 가지므로 $50^2x = 2,500x$ 배 증가하게 된다.
- 그러나 빠른 곱셈 알고리즘 (Fast Multiplication)을 적용하면 복잡도는 O(nlog n) 수준으로 개선되어 $(50 \log 50)x ≈ 2,000x$ 정도로 줄어든다.
👉 따라서, 키 길이를 $50$배 늘려도 계산량은 약 $2,000$배 증가하게 된다. 즉, 보안 강도를 높이는 것은 필연적으로 연산 비용 증가를 수반한다.
- 물론 위 계산은 최적화가 잘 이루어진 경우를 가정한 것이다. 실제로는 알고리즘과 구현 수준에 따라 성능 편차가 크며, 이러한 최적화(optimization)는 인공지능이 아니라 사람이 직접 설계해야 한다. 다시 말해, 알고리즘적·구현적 튜닝이 부족한 경우에는 여전히 수천 배에서 수만 배까지 느린 사례도 존재한다.
2) 동형암호의 종류
정수 기반 동형암호 (Integer-based HE scheme)
동형암호의 초기 형태는 **정수 연산 기반**으로 설계되었습니다. 대표적으로 RAD PH와 DGHV 스킴이 있습니다.
해당 포스트는 서울대학교 천정희 교수님의 암호론 강의를 기반으로 작성하였다. 이번 포스트에서는 ‘공개키암호의 안전성’에 대한 내용을 요약•정리하고자 한다.
1. 공개키암호의 안전성 개념 (Security of Public-Key Cryptosystems)
1) 공개키암호의 안전성 개념
Targets
One-wayness (OW): 역연산이 어려움 (hard to invert) $\rightarrow$ 평문($e$)에서 암호문($c$)으로 갈 수 있지만 반대로는 불가하다! (그렇지만 평문이 짝수인지 홀수인지 알 수 있다는 것을 알게 됨ㅠ)
Semantically Secure (Indistinguishable: IND): 부분 정보 노출 없음 (no partial information) - 암호문 $c = E(m)$을 통해, 공격자가 평문 $m$에 대한 어떤 부분 정보도 추론할 수 없어야 한다. - 즉, 암호문이 평문의 성질(예: 짝수/홀수, 길이, 특정 비트 값 등)을 드러내면 안 된다. - 이를 만족할 때, 암호문은 평문에 대한 정보를 전혀 새지 않고 무작위처럼 보인다고 말한다.
Non-malleability (NM): 암호문으로부터 의미 있는 변형을 만들기 어려움 - $R$: 어떤 non-trivial relation (비자명한 관계) - $E(M)$: 평문 $M$의 암호문 - NM조건: 공격자가 $E(M)$을 보고도 $E(R(M))$을 얻는 게 어렵다. $\rightarrow$ 암호문을 변형해서 원래 평문과 관련된 다른 유효한 평문의 암호문을 얻을 수 없어야 한다. $\Rightarrow$ Semantically Secure하지 않으면, Indistinguishable하지 않다!
📘 Indistinguishable 고차원 개념
정의 암호체계가 indistinguishable 하다는 것은 공격자가 두 개의 평문 $m_0, m_1$ 중에서 임의로 하나를 선택 후, 암호문 $E(m_b)$을 만들어서 $(m_0, m_1, E(m_b))$ 으로부터 $b$ 의 정보를 얻는 것이 어려워야 한다는 것을 의미한다.
Attacks
Passive attacks (Chosen Plaintext Attack: CPA)
Active attacks (Chosen Ciphertext Attack: CCA)
2) Semantic Security (Indistinguisability: IND)
단계
공격자가 두 평문 $m_0, m_1$ 을 선택한다.
공격자는 무작위 비트 $b \in {0,1}$ 을 선택해서, 암호문 $c=E(m_b)$을 얻는다.
공격자는 $(m_0, m_1, c)$ 를 바탕으로 $b$를 추측한다.
공격자의 추측 $b’$ 가 실제 $b$와 같을 확률은 무작위 추측 수준($\frac{1}{2}$)을 유의미하게 넘지 않아야 한다.
[그림] IND 실험: 공격자는 $c = E(m_b)$를 보고 $b$를 추측해야 한다.
\(\therefore \Pr[b = b'] \leq \tfrac{1}{2} + \text{negl}(n)\) (여기서 $\text{negl}(n)$은 보안 매개변수 $n$에 대해 무시 가능한 값이다.)
3) Chosen Ciphertext Attack (CCA)
CCA1 (Lunch time attack, Naor-Yung, ‘90)
공격자가 능동적 공격을 끝낸 후 암호문 $C_0$을 얻을 수 있는 상황
CCA2 (Rackoff - Simon, ‘91)
공격자가 능동적 공격을 시작하기 전에 암호문 $C_0$을 얻을 수 있는 상황
[그림] 선택 암호문 공격(CCA) 모형: 공격자는 복호화 오라클을 통해 다양한 암호문 $C_1, \cdots, C_n$에 대한 평문 정보를 얻지만, 목표 암호문 $C_0$에 대해서는 직접 복호화를 요청할 수 없다.
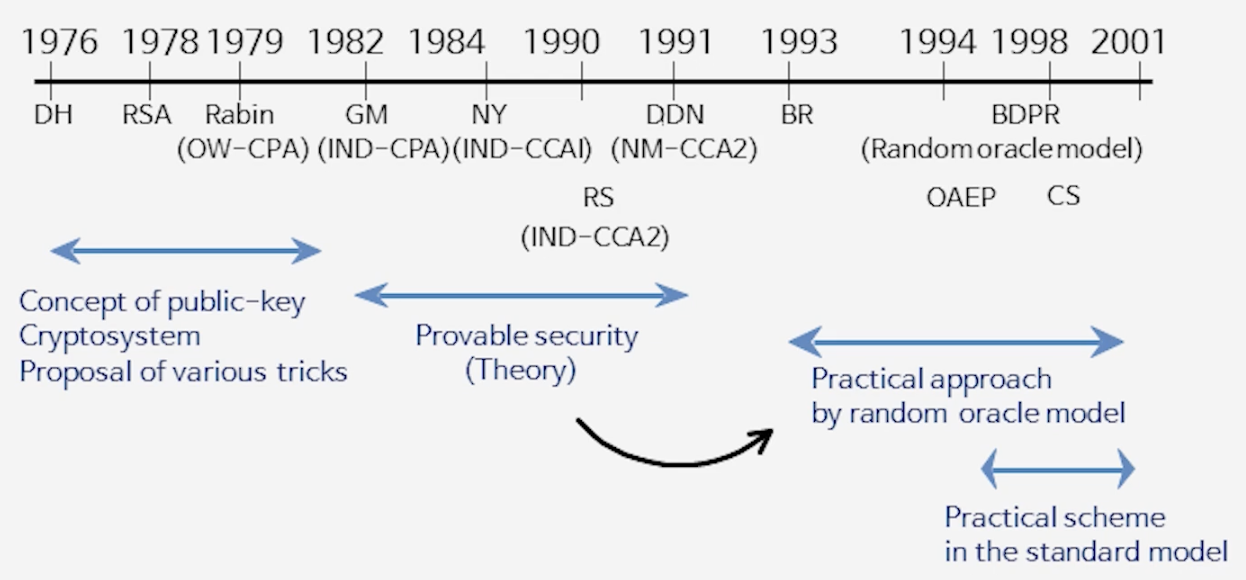
4) 공개키암호의 안전성 발전 역사
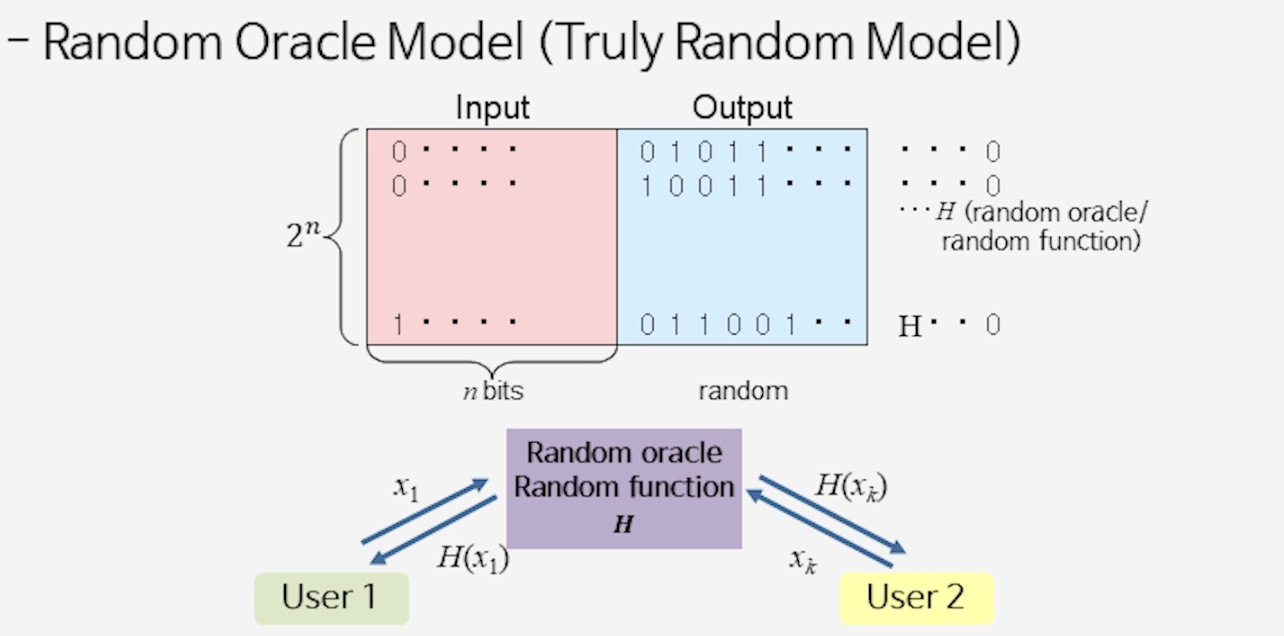
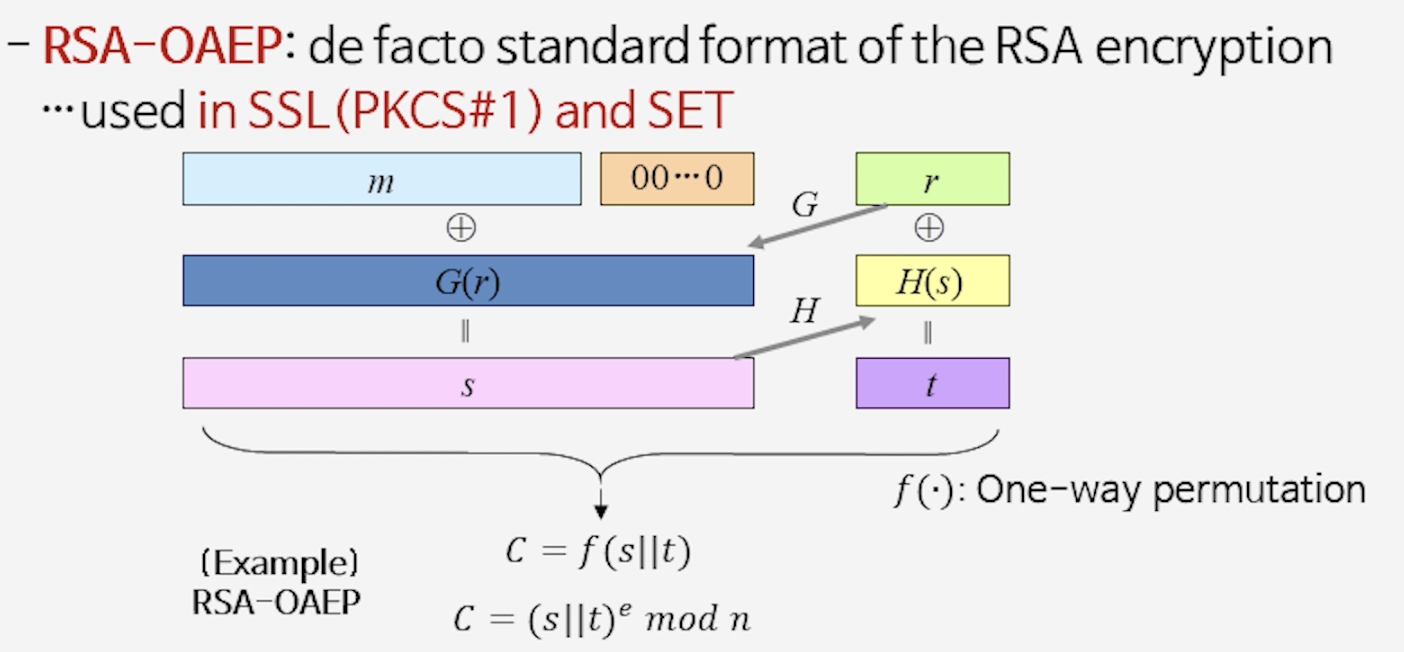
[그림] 공개키 암호 안전성의 역사: 1976년 Diffie–Hellman에서 시작하여, 1990년대 IND-CCA2 보안 정의, Random Oracle Model, OAEP, CS 체계까지의 발전 과정
5) 가장 강력한 보안 (IND-CCA2) 암호체계 구성 방법
Zero-Knowledge Proof 기반
Dolev–Dwork–Naor (1991)
$\Rightarrow$ 비효율적 (Inefficient)
랜덤 오라클 모델 기반 (truly random function 가정)
Bellare–Rogaway: OAEP (1994), PKCS#1–Ver.2 (1998)
대담한 가정: 해시 함수가 랜덤 함수와 구별 불가하다면 → 안전성 증명 가능!
물론 이 가정은 거짓. 해시 함수는 랜덤 함수처럼 작동하지만 실제로는 다르다.
📘 그럼에도 의미가 있었던 이유
그런 가정 위에서 RSA의 안전성을 처음으로 증명할 수 있었음
잘못된 가정을 출발점으로 했지만, 이후 점차 약한 가정을 사용하며 진짜 증명에 도달
“틀린 가정이라도 증명 기법 발전의 촉매제 역할”을 했다는 점에서 큰 의의
Fujisaki–Okamoto (1999), Pointcheval (2000)
Okamoto–Pointcheval: REACT (2001)
$\Rightarrow$ 실용적 (Practical): 실제로는 무작위 함수 대신 일방향 함수(one-way functions)를 사용
랜덤 함수 없이도 가능한 실용적 구성
이산로그에 기반한 Cramer–Shoup (1998) → 표준 모델에서 처음으로 IND-CCA2 안전성을 만족하는 실용적 공개키 암호체계
6) Naïve RSA와 ElGamal의 안전성
RSA는 malleable (변형 가능)하다. 📘 malleable 의미
RSA에서 $c = m^e \pmod{n}$ 일 때, \(2^{e} \cdot c \equiv (2m)^e \pmod{n}\)
→ 공격자는 원래 메시지 $m$을 몰라도, $2m$에 해당하는 새로운 암호문을 쉽게 만들 수 있다. → 즉, 암호문에서 평문과 연관 있는 다른 암호문을 생성할 수 있으므로 Non-malleability(NM)를 만족하지 못한다.
ElGamal (유한체 위에서 정의된 경우) → IND 보안(Indistinguishability)을 만족하지 않는다. 📘 왜 IND가 깨지는가?
ElGamal 암호문은 $(g^r, m \cdot h^r)$ 꼴이다.
여기서 $g$는 생성원(generator), $r$은 랜덤 값.
하지만 공격자는 두 번째 성분을 통해 메시지가 $g$의 짝수 지수 꼴인지, 홀수 지수 꼴인지 판정할 수 있다.
→ 따라서 평문에 대한 일부 정보가 노출되어, 구별 불가능성(IND)이 깨진다.
EC-ElGamal (타원곡선 기반) → IND-CCA2 보안을 만족하지 않는다.
📘 추가 설명: Generic Group vs Elliptic Curve Group
Generic Group Model (제네릭 군 모델) 공격자가 군의 원소를 다루지 못하고, 단지 "블랙박스 연산(곱셈·역원·동등성 검사)"만 가능하다고 가정 → 이 모델에서는 ElGamal이 IND-CPA 보안을 만족한다.
Elliptic Curve Group (타원곡선 군, 실제 구현) 실제 타원곡선 구조에서는 공격자가 곡선의 수학적 성질을 활용할 수 있음 즉, 공격자가 구체적인 타원곡선 구조를 활용한 공격도 가능해짐 → 따라서 EC-ElGamal은 강한 보안(특히 IND-CCA2)을 만족하지 못한다.
7) Secure Conversion: 실용적이고 안전한 암호 만들기
Primitive 암호체계 (예: RSA, ElGamal) → 그대로 버리는 것이 아니라, 이를 기반으로 변환(conversion)을 적용할 수 있다.
아이디어:
primitive가 특정 조건 (예: trapdoor one-way, IND-CPA)을 만족하면
변환 상자(conversion)에 넣어 자동으로 IND-CCA2 안전한 암호체계를 얻을 수 있음 → 이를 secure conversion이라 부른다.
연구적 의미:
primitive의 안전성 증명 (예: trapdoor one-way, IND-CPA)는 비교적 쉽다.
하지만 IND-CCA 보안 증명/설계는 어렵다.
따라서 연구자들은 “IND-CPA 스킴 → conversion 적용 → IND-CCA2 스킴” 방식으로 접근했다.
📘 IND-CPA (Chosen Plaintext Attack 보안)
공격자가 원하는 평문 $m_0, m_1$을 선택한다.
암호문은 무작위로 선택된 $m_b$의 암호문 $c = E(m_b)$로 주어진다.
공격자의 목표: $b \in {0,1}$을 맞추는 것.
IND-CPA 보안 조건: \(\Pr[b = b'] \leq \tfrac{1}{2} + \text{negl}(n)\) → 무작위 추측과 유의미하게 구별되지 않아야 한다.
→ 암호문만 보고도 평문을 알아내기 어려워야 한다.
📘 IND-CCA2 (Chosen Ciphertext Attack 보안)
공격자는 복호화 오라클을 이용해 임의의 암호문 $c_1, \dots, c_n$을 복호화해볼 수 있다.
단, 목표 암호문 $c^*$ 자체는 복호화할 수 없다.
목표: $c^* = E(m_b)$에 대해 $b \in {0,1}$을 맞추는 것.
IND-CCA2 보안 조건: \(\Pr[b = b'] \leq \tfrac{1}{2} + \text{negl}(n)\) → 복호화 오라클을 쓸 수 있어도 무작위 추측 수준 이상 맞출 수 없어야 한다.
→ 암호문만 보는 게 아니라, 다른 암호문을 복호화해보는 강력한 능력을 줘도 여전히 평문을 알아내기 어려워야 한다.
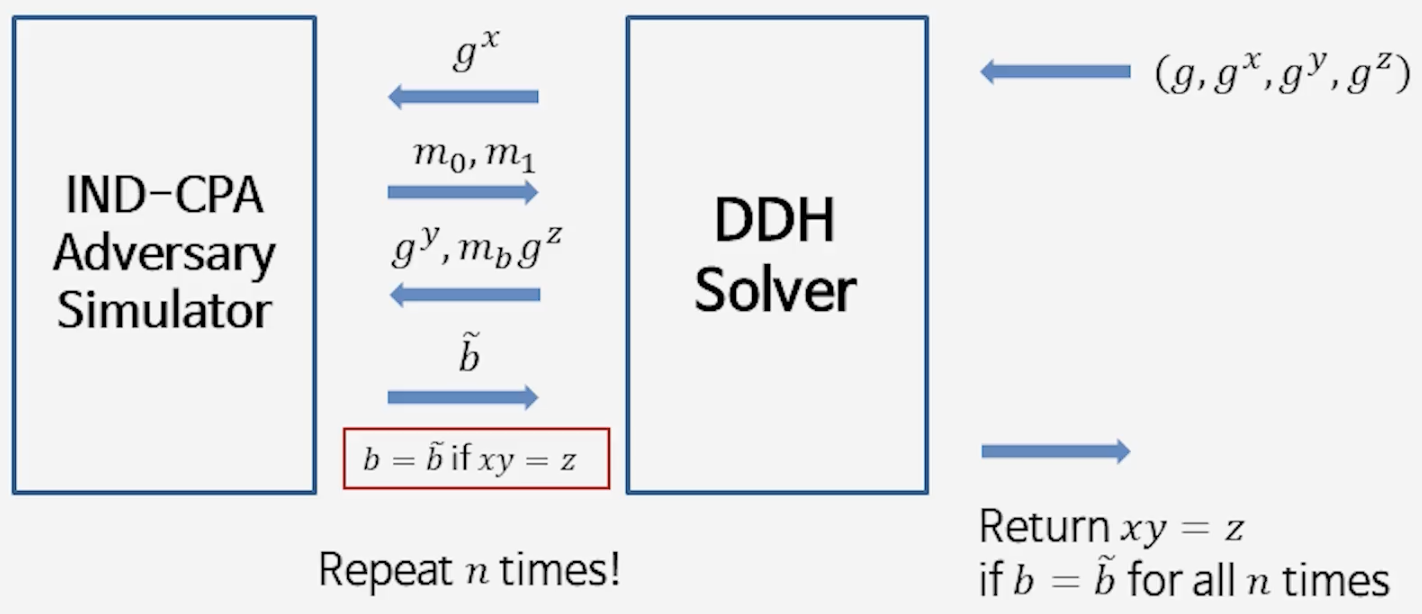
2. ElGamal의 IND-CPA 안전성 (IND-CPA Security of ElGamal)
1) ElGamal의 IND-CPA 안전성 정의
$G$: 소수 차수 $p$를 갖는 (순환) 가환군, 생성원 $g \in G$
DDH 문제 (Decision Diffie–Hellman) $\colon$ 주어진 $(g, g^x, g^y, g^z)$에 대해 $z \stackrel{?}{=} xy \pmod p$를 판정
📘 ElGamal과 DDH의 관계
**“ElGamal이 깨지면 DDH도 깨진다 → 따라서 DDH가 안전하면 ElGamal도 안전하다”
Interactive Assumption (상호작용 가정)
ElGamal의 안전성을 정의하려면 공격자(Adversary)와 도전자(Challenger)가 메시지를 주고받는 시나리오를 설정해야 한다.
수학적으로 깔끔하게 표현하기 어려워, 공격자가 존재하지 않는다는 식으로만 보안을 표현할 수 있다.
Non-Interactive Assumption (비상호작용 가정)
반면 DDH 문제는 단순하다.
주어진 $(g, g^x, g^y, g^z)$가 Diffie–Hellman를 만족하는 지 판별하기만 하면 된다.
공격자와의 상호작용이 필요 없고, 문제 자체를 풀 수 있느냐 없느냐만 보면 된다.
2) ElGamal의 IND-CPA 보안 실험
도전자 $C$가 비밀키 $k \xleftarrow{$} \mathbb{Z}_p$를 뽑고 공개키 $g^k$를 만든다.
해당 포스트는 서울대학교 천정희 교수님의 암호론 강의를 기반으로 작성하였다. 이번 포스트에서는 ‘공개키암호와 RSA’에 대한 내용을 요약•정리하고자 한다.
1. 공개키암호 (Public-Key Cryptography)
1) One-way Function
$x$가 주어졌을 때, $f(x)$를 계산하긴 쉽지만, $f(x)$가 주어졌을 땐 $f^{-1}(x)$를 계산하는 것은 어렵다. $e.g.)$ 큰 수의 소인수분해 → $pq$ 계산은 쉽지만, $n=pq$ 일 때, $p$ 와 $q$ 를 찾는 것은 어렵다.
🎯 깜짝 퀴즈 🎯
일방향 함수만 있으면 공개키 암호를 만들 수 있을까? → Open Problem (단, 전자서명은 일방향 함수만 있어도 만들 수 있다는 것이 증명됨)
2) Trapdoor One-way Function
공개키 암호는 “누구나 암호화할 수 있고, 특정 비밀키로만 복호화할 수 있어야” 한다.
즉, 일방향 함수에 추가로 특별한 비밀 정보(Trapdoor Information, 일종의 열쇠 🔑)가 주어진다면, $y$가 주어졌을 때, $f^{-1}(y)$는 쉽게 계산할 수 있다.
3) Diffie-Hellman 키 교환
두 사람이 공개된 통신로를 통해 비밀 정보를 공유하는 방법
초기화 (변수 생성후 공개) • 소수 $q$ ($q-1$ 이 큰 소수 약수를 가짐 - $e.g.) q=23, q-1=22=2 \times 11$) • $q$ 보다 작은 자연수 $g$
과정 • Alice: 개인키 $a$, 공개키 $A = g^a \pmod{q}$ • Bob: 개인키 $b$, 공개키 $B = g^b \pmod{q}$ • Eve (도청자): $g^a, g^b$에서 $a, b$ 정보를 알아내는 것은 어렵다. ※ 비밀키 $a, b \in \mathbb{Z}_p \;\; (0 \leq a, b < p \;\text{ 또는 }\; -\tfrac{p}{2} \leq a, b < \tfrac{p}{2})$
공통 비밀키 생성 • Alice는 $a, g^{b}$로 $g^{ab}$ 를 계산할 수 있다. • Bob은 $b, g^{a}$로 $g^{ba}$ 를 계산할 수 있다. ※ 단, $g^{ab} = g^{ba}$ 이 성립하려면 연산 구조가 가환군(Commutative Group) 이어야 한다.
안전성 • Eve는 $(g, g^a, g^b)$ 만으로는 $g^{ab}$ (공통 비밀 정보)를 계산하기 어렵다. → 이를 이산 로그 문제(Discrete Logarithm Problem) 라고 한다.
🔎 왜 "이산 로그 문제"가 어려운가?
• 만약 모듈러 $p$ 없이 정수 지수승이라면: $g^1, g^2, g^3, \dots$ 의 값은 계속 커지고, 대략 몇 번 곱했는지 추측할 수 있음 → 여러 번 반복하면 로그 값(지수)을 조금씩 알아낼 수 있다.
• 그러나 모듈러 $p$ 연산을 하면: $g^a \pmod{p}$는 $0 \sim p-1$ 범위 안에서 뒤섞여(cycle) 나타남 → 출력 값만 보고는 $a$의 크기를 추측할 단서가 사라진다.
• 따라서 $y = g^a \pmod{p}$에서 $a$를 찾는 문제는 현재로써는 지수 시간이 걸린다.
📌 정리 • 정수 로그: 크기 비교로 추측 가능 → 쉽다. • 이산 로그(mod p): 값이 wrap-around 되므로 추측 불가 → 어렵다. • Diffie–Hellman 키 교환의 안전성은 바로 이 DLP의 난이도에 기반한다.
🎯 깜짝 퀴즈 🎯
Discrete Logarithm 문제가 안전하면 Diffie-Hellman 문제는 어려울까? 혹은 Diffie-Hellman 문제를 풀 수 있다면 Discrete Logarithm 문제도 풀릴까? → Difficult Problem
[ DL과 DH의 관계 ] • DL: $(g, g^a)$ 를 알 때 → $a$ 를 안다. • DH: $(g, g^a, g^b)$ 를 알 때 → $g^{ab}$ 를 안다.
- 항상 성립: DL이 풀면 DH도 풀 수 있다. → 왜냐하면 $a$나 $b$를 알면 바로 $g^{ab}$를 계산할 수 있기 때문 - 미해결 문제: DH가 풀면 DL도 풀 수 있다. → 일반적으로는 아직 알려지지 않은 Open Problem - 특별한 경우: $g$의 order = $p$인 경우, • $\mathbb{DL}_p = \mathbb{DH}_p,$ $if$ $\exists$ an elliptic curve $E$ over $\mathbb{Z}_p$ $s.t.$ $|E(\mathbb{Z}_p)|$ is smooth. → 만약 어떤 타원곡선 $E$가 유한체 $\mathbb{Z}_p$ 위에 정의돼 있고, 그 점들의 개수 $|E(\mathbb{Z}_p)|$가 smooth하다면, DL 문제와 DH 문제가 동치라는 결과가 알려져 있다. → 충족하는 것을 찾는 데 걸리는 시간 $\neq$ 다항식 시간 ※ $g$의 order(위수)란 "$g$를 계속 곱하다 보면 언젠가 처음 상태(1)로 돌아오는데, 그때까지 몇 번 곱해야 돌아오는지"를 의미한다. → 즉, 사이클 길이라고 이해하면 된다. ※ smooth란 큰 소수(prime number) 없이 작은 소수들만 곱한 것을 의미한다. → 예. 840 = $2^3 \cdot 3 \cdot 5 \cdot 7$
📌 쉽게 말하면, - 평소엔 DL이 더 어려운 문제일 수도 있다. - 하지만 특정 조건(타원곡선 위 점 개수가 smooth할 때)에서는 → DH와 DL이 사실상 같은 난이도의 문제로 수렴한다.
• 여기서 $pk = g^b$, $b$: Bob의 개인키, $r$: Alice가 매 메시지마다 선택하는 난수 • ElGamal의 $G$는 “mod $p$에서의 곱셈군” $\mathbb{Z}_p^*$ 을 뜻한다
🎯 깜짝 퀴즈 🎯
Q. ElGamal 암호화에서 sk = $b$, pk = $g^{b}$ 일 때, • \(\mathrm{Enc}_{pk}: \mathbb{Z}_p \longrightarrow G \times G\) • \(m \;\mapsto\; (g^r,\; g^{rb}\cdot m)\) → 복호화하기 위해서 필요한 정보는 무엇일까?
A. 바로 Bob의 개인키 $b$ 이다. $(g^r, g^{rb}\cdot m)$에서 $m$을 되찾으려면 $g^{rb}$를 알아야 하고, 이를 계산할 수 있는 유일한 정보가 $b$ 다.
→ 따라서 $b$ 가 Trapdoor (비밀 열쇠) 역할을 한다.
⚠️ 단, 그렇다 해서 Trapdoor One-way Function 은 아니다. → 왜냐하면 ElGamal은 항상 같은 $f(x)$를 내는 고정된 함수가 아니라, 매번 임의의 $r$을 뽑아 다른 출력이 나오는 확률적 암호화 방식이기 때문이다. 즉, 수학적 함수라기보다는 암호화 스킴 전체에서 “거꾸로 갈 수 있게 해주는 비밀키”라는 의미로 트랩도어처럼 동작한다.
🔑 정리 🔑 • Trapdoor One-way Function → “일방향만 쉽다.” (단, 비밀 정보(Trapdoor)가 있으면 거꾸로도 쉽다.)
• 공개키 암호 (PKC) → “누구나 공개키로 암호화는 쉽게 할 수 있지만, 복호화는 어렵다.” (단, 비밀키가 있으면 복호화가 쉽다.”)
∴ 즉, 구조적으로 보면 공개키 암호(PKC) ≈ Trapdoor One-way Function이다. → 다만 수학적으로 정확히 동치 라기보다는, PKC가 성립하려면 TOWF가 존재해야 한다는 의미에서 개념적 동치로 본다.
Elliptic Curve based scheme / Hidden Field Equations / Lattice Cryptography / Non-abelian group Cryptography / Fully Homomorphic Encryption
Hard Problems for PKC
Integer Factorization Problem (IFP) • 큰 수 $n = pq$ 를 소인수분해하는 문제 • 관련: Quadratic Residuocity Problem
Discrete Logarithm Problem (DLP) • $y = g^x \pmod p$에서 $x$를 구하는 문제 • 확장: Generalized DLP (Elliptic Curve, Hyperelliptic Curve, Class Field)
Linear Code Decoding
Multivariate Equations • 여러 변수에 대해 2차 이상의 다항식을 푸는 문제 • 일반형: \(\begin{cases} f_{1}(x_{1}, ..., x_{n}) = a_{1} \\ f_{2}(x_{1}, ..., x_{n}) = a_{2} \\ \vdots \\ f_{n}(x_{1}, ..., x_{n}) = a_{n} \end{cases}\) → 1차(선형)일 경우, 가우스 소거법으로 $O(n^3)$ 안에 풀림 → 2차 이상일 경우, NP-hard (실질적으로 매우 어려움) • 관련: Hidden Field Equations, Isomorphism of Polynomials
Nonabelian Group (비가환군) • Conjugacy Problem (켤레 문제): $a, b$가 주어졌을 때 $x^{-1}ax = b$인 $x$를 찾는 문제 • Decomposition Problem: 주어진 원소를 이루는 생성자들의 곱으로 분해하는 문제 ※ 다만, 행렬군에서는 다항 시간 내로 풀려서, Braid Group(꼬임군) 등 다른 구조 사용
Lattice 기반 문제 • SVP (Shortest Vector Problem): 주어진 격자에서 가장 짧은 벡터 찾기 • CVP (Closest Vector Problem): 주어진 점에 가장 가까운 격자 벡터 찾기 • 파생 문제들: • Learning with Errors (LWE): $y = Ax + e \pmod q$에서 $x$를 찾는 문제 (작은 오류 $e$ 포함) • Approximate Common Divisor (ACD): 약간의 노이즈가 있는 공약수 문제
→ 다만, 아직까지 NP-hard 문제를 기반으로 한 암호 스킴은 실용적으로 설계하진 못함
📚 참고 자료 모아보기
1) 공개키 암호가 생겨난 이유
대칭키 암호(Symmetric Cryptosystem)의 한계 • 모든 통신 쌍이 서로 다른 비밀키를 공유해야 안전함 • 참가자 수가 $n$일 때 필요한 키 개수는 조합으로 계산됨: $\binom{n}{2} = \frac{n(n-1)}{2}$. • 예: $n = 100 → 4,950$개의 키 필요 • 규모가 커질수록 키 관리가 폭발적으로 어려워짐
발명 동기 • “비밀키를 미리 공유하지 않고도 안전하게 통신할 수 없을까?” → Diffie & Hellman의 아이디어 • 여기서 나온 개념이 바로 공개키 암호(PKC)
공개키 암호의 혁신 • 공개키: 누구나 알 수 있음 → 암호화에 사용 • 비밀키: 당사자만 알고 있음 → 복호화에 사용 • 따라서 키를 미리 비밀리에 나눌 필요 없음 → 키 관리 문제 해결
2) Merkle’s Puzzle (1974)
최초로 “공개키 개념”을 제안한 시도
Ralph Merkle, UC Berkeley 컴퓨터 보안 수업(1974) 제안
논문: Secure Communication over Insecure Channels (CACM, 1978)
Merkle Puzzle 아이디어 • 많은 퍼즐 중 하나를 선택해 해결 → 두 당사자만 공유하는 비밀키 획득 • 공격자는 퍼즐을 전부 풀어야 하므로 비용이 급격히 증가 • 다만 차이가 “1000배 수준(다항시간 내에 해결 가능)”이라 실제 보안성은 부족
📌 교훈: • 퍼즐 수를 늘리면 안전성은 기하급수적으로 증가 • 이 아이디어가 이후 Diffie–Hellman 키 교환으로 발전
📌 암호학적 핵심: • 앞으로 계산은 쉽다 (다항 시간) • 거꾸로 풀기는 어렵다 (지수 시간) • RSA: 곱셈은 빠름, 소인수분해는 어렵다 • 격자 기반 암호: Lattice 문제의 난이도 활용
P vs NP • P: 다항 시간(Polynomial time) 안에 풀 수 있는 문제 • NP: 답이 맞는지 검증은 다항 시간 안에 가능(Non-deterministic Polynomial) • P ⊆ NP, NP-complete = NP ∩ NP-hard • 만약 P = NP라면, 현재 암호 시스템 대부분이 무너짐 (소인수분해, 이산 로그 등도 다항 시간에 풀리게 됨) • 아직까지 전 세계적으로 해결되지 않은 컴퓨터 과학 최대 난제 중 하나.
대표적인 어려운 문제들 • TSP (Traveling Salesman Problem) 도시 목록과 거리 정보가 주어졌을 때, 모든 도시를 정확히 한 번 방문하는 가장 짧은 경로를 찾는 문제
• SSP (Subset Sum Problem) 정수 집합이 주어졌을 때, 어떤 부분집합의 합이 정확히 0이 되는지 묻는 문제
• Integer Factorization 큰 수 (n = pq)를 소인수분해하는 문제 (RSA 안전성의 기반)
2. RSA (Rivest-Shamir-Adleman)
1) Prime
📘 Prime (소수)와 Euclid의 정리
- Prime (소수) 기본 개념
소수 정의 $p \geq 2$ 인 정수 $p$가 소수일 경우, \(a \mid p \;\Rightarrow\; a = \pm 1 \;\;\text{또는}\; \pm p\) 를 만족 → 즉, 약수가 1과 자기 자신밖에 없음
Irreducible (기약원) $p = ab$ 를 인수분해했을 때, $a$ 또는 $b$ 중 하나가 단위원(unit, 즉 $\pm 1$) 일 때, $p$ 를 기약원이라고 함 → 정수에선 기약원 = 소수라고 생각하면 됨
- Euclid의 정리
Euclid’s Lemma \(p \mid ab \;\;\Rightarrow\;\; p \mid a \;\;\text{또는}\;\; p \mid b\) → 소수의 중요한 성질! (소수는 약간 “쪼갤 수 없는 블록”이라는 뜻)
$x = 3^{100}$ (약 $10^{47.7}$ 크기의 수, 48자리 수 정도): \(\frac{1}{\ln(3^{100})} = \frac{1}{100 \ln 3} \approx \frac{1}{110}\) → 따라서 $3^{100}$가 소수일 확률은 약 $\frac{1}{110}$
일반 소수 정리의 오차항
\(\pi(x) = \frac{x}{\ln x} + O\left(\frac{x}{\ln^2 x}\right)\) → 즉, 실제 소수 개수는 $\dfrac{x}{\ln x}$에 가깝지만, 그 차이는 대략 $\dfrac{x}{\ln^2 x}$ 정도 크기